
Whilst, as of the time of writing, the Snowflake-Streamlit integration isn’t here yet, FrostyFriday sees that as only more reason to get ahead of the curve and start developing those Streamlit skills.
While Streamlit is Python-based, and we encourage you to learn Python, this challenge is Python-optional. The skeleton script below should mean you can do this challenge without any Python knowledge.
For a guide on getting started, head over here.
So…what’s the challenge?
Well, a company has a nice and simple payments fact table that you can find here. They want FrostyData to help them by ingesting the data and creating the below line chart.
Result:
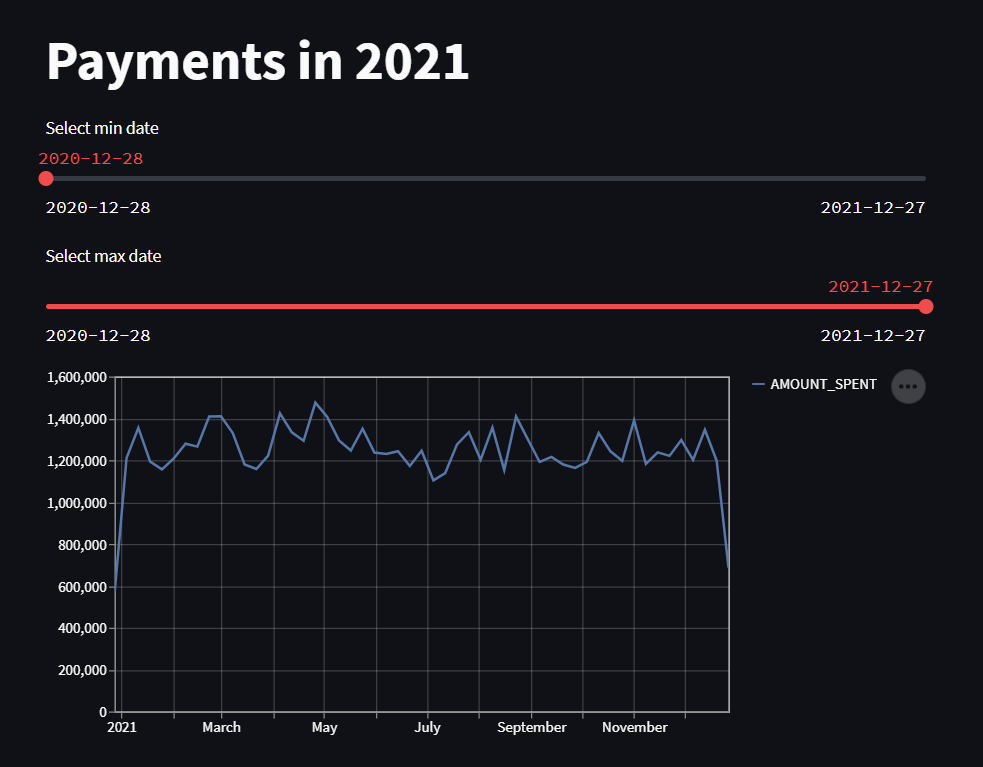
- The script must not expose passwords, as this would be very unsafe, instead, it should use Streamlit secrets.
- The title must be “Payments in 2021”.
- It must have a ‘min date’ filter which specifies the earliest date a user can select, by default this should be set to the earliest date possible.
- It must have a ‘max date’ filter which specifies the latest date a user can select, by default this should be set to the latest date possible.
- It should have a line chart with dates on the X axis, and amount on the Y axis. The data should be aggregated at the weekly level.
Skeleton Script for non-Python Users:
import streamlit as st
import pandas as pd
import snowflake.connector
# Normally, a secrets file should be saved in C:\Users\<your_user>\.streamlit
# as secrets.toml
ctx = snowflake.connector.connect(
user="""<enter username here using a secrets.toml file>""",
password="""<enter password here using a secrets.toml file>""",
account="""<enter account here using a secrets.toml file>"""
)
cs = ctx.cursor()
# WARNING - When aggregating columns in this query, keep the column names the same.
query = """<enter SQL here>"""
@st.cache # This keeps a cache in place so the query isn't constantly re-run.
def load_data():
"""
In Python, def() creates a function. This particular function connects to your Snowflake
account and executes the query above. If you have no Python experience, I recommend leaving
this alone.
"""
cur = ctx.cursor().execute(query)
payments_df = pd.DataFrame.from_records(iter(cur), columns=[x[0] for x in cur.description])
payments_df['PAYMENT_DATE'] = pd.to_datetime(payments_df['PAYMENT_DATE'])
payments_df = payments_df.set_index('PAYMENT_DATE')
return payments_df
payments_df = load_data() # This creates what we call a 'dataframe' called payments_df, think of this as
# a table. To create the table, we use the above function. So, basically,
# every time your write 'payments_df' in your code, you're referencing
# the result of your query.
def get_min_date():
"""
This function returns the earliest date present in the dataset.
When you want to use this value, just write get_min_date().
"""
return min(payments_df.index.to_list()).date()
def get_max_date():
"""
This function returns the latest date present in the dataset.
When you want to use this value, just write get_max_date().
"""
return max(payments_df.index.to_list()).date()
def app_creation():
"""
This function is the one your need to edit.
"""
# <Create a title here>
min_filter = # <Create a slider for the min date>
max_filter = # <Create a slider for the max date>
mask = (payments_df.index >= pd.to_datetime("""<your minimum filter should go here>""")) \
& (payments_df.index <= pd.to_datetime("""<your maximum filter should go here>"""))
payments_df_filtered = payments_df.loc[mask] #This line creates a new dataframe (table) that filters
# your results to between the range of your min
# slider, and your max slider.
# Create a line chart using the new payments_df_filtered dataframe.
app_creation() # The function above is now invoked.Remember if you want to participate:
- Sign up as a member of Frosty Friday. You can do this by clicking on the sidebar, and then going to ‘REGISTER‘ (note joining our mailing list does not give you a Frosty Friday account)
- Post your code to GitHub and make it publicly available (Check out our guide if you don’t know how to here)
- Post the URL in the comments of the challenge.
12 responses to “Week 8 – Basic”
-
I’m a late joiner here, but thanks for all the exercises.
This is a fun way to learn.My repo: https://github.com/mateusz-kmon/frostyfridaychallenges
-
I had fun with this one as I haven’t used Streamlit before. Probably spent far more time that I needed to created a shared snowpark subdirectory in my repo that can leverage locally-stored authentication keys via a path in the streamlit secrets, but I think it was worth the time!
The streamlit part:
https://github.com/ChrisHastieIW/Frosty-Friday/tree/main/Week%208%20-%20Basic%20-%20StreamlitThe snowpark part for anybody interested:
https://github.com/ChrisHastieIW/Frosty-Friday/tree/main/shared/snowpark#connection-parameters-
Reorganised my submission repo, new master solution URL here.
- Solution URL – https://github.com/ChrisHastieIW/Frosty-Friday
-
-
This was interesting, let’s see it in action again when all this can be accomplished entirely within SF (then it would be possible to have it all dbt-contained, which is not possible atm)
Streamlit:
https://github.com/dsmdavid/frostyfridays-sf/blob/main/extra/ch_08_streamlit.py
and the model:
https://github.com/dsmdavid/frostyfridays-sf/blob/main/models/challenge_08.sql -
I initially had a working version which would query every single time the sliders were moved. Then looking at the docs and other solutions, I realised I should query once, cache the data and then filter it dynamically based on the sliders. I wonder how performant this is on much bigger data sets!
- Solution URL – https://github.com/ChrisBBiztory/FrostyFriday/tree/main/Streamlit
-
Nice challenge to learn more about Streamlit!
- Solution URL – https://github.com/pekka-kanerva/frosty-friday/tree/main/week8
-
A good one to start getting familiar with Streamlit!
Adding the solution also here since it has 2 parts:
SQL: https://github.com/Atzmonky/snowflake/blob/main/ch8_Streamlit.sql
Python: https://github.com/Atzmonky/snowflake/blob/main/ch8_Streamlit.py
Challenge Blog: https://theinformationlab.nl/en/2022/10/19/streamlit-integration-in-snowflake/- Solution URL – https://github.com/Atzmonky/snowflake/blob/main/ch8_Streamlit.py
-
Here’s my solution, again with kudos to @Atzmonky for the excellent explainer
SQL: https://github.com/apd-jlaird/frosty-friday/blob/main/week_8/ff_week_8.sql
Python: https://github.com/apd-jlaird/frosty-friday/blob/main/week_8/ff_week_8.py
App screenshot: https://raw.githubusercontent.com/apd-jlaird/frosty-friday/main/week_8/app_screenshot.jpg
- Solution URL – https://github.com/apd-jlaird/frosty-friday/tree/main/week_8
-
Love Streamlit!
- Solution URL – https://github.com/canonicalized/FrostyFriday/blob/main/WEEK8.py
-
Spent a lot of time on this one! I wanted to set everything up in Snowsight (Streamlit Apps), since that is possible now. I also wanted to include setting up the stage and table with Snowpark, which was interesting as well.
https://github.com/marioveld/frosty_friday/tree/main/ffw8
- Solution URL – https://github.com/marioveld/frosty_friday/tree/main/ffw8
-
🙂
- Solution URL – https://github.com/darylkit/Frosty_Friday/blob/main/Week%208%20-%20Streamlit/payments.sql
-
This challenge is basic but learnfully. I enjoyed it very much!
I also made a solution using LLMs, but it’s a joke one!- Solution URL – https://github.com/Sakatoku/Frosty-Friday/blob/main/week8_basic_streamlit/

{kind=link}
Leave a Reply
You must be logged in to post a comment.