
This week we’re working with small dataset about house sales that needs to be categorized according to certain sliding bins. The catch however , is that the sizes and the number of bins can change quickly.
The challenge is to create a function with a single name that does the following:
- can handle uneven bin sizes
- the first parameter must be the column that will inform your bins (in this example, we categorise according to [price])
- the second parameter should specify the ranges of your bins (remember, these are uneven bins, bin 1 could be 1 – 400, and bin 2 401 – 708, while bin 3 is 709 – 3000) how you do this is up to you: you can specify lower bounds, upper bounds, both, count within each bin….
- if using SQL, as a minimum, it should be able to handle 2-6 bins, if using other languages then you will find them flexible enough to allow you to do any number of bins
The query should look like the following :
SELECT sale_date,
price,
your_function(price,<bin_ranges>) AS BUCKET_SET1,
your_function(price,<bin_ranges>) AS BUCKET_SET2,
your_function(price,<bin_ranges>) AS BUCKET_SET3,
FROM home_salesYou will then need to pass in the following bin/bucket ranges for testing purposes:
- Bucket_Set1:
- 1: 0 – 1
- 2: 2 – 310,000
- 3: 310001 – 400000
- 4: 400001 – 500000
- Bucket_Set2:
- 1: 0 – 210000
- 2: 210001 – 350000
- Bucket_Set3:
- 1: 0 – 250000
- 2: 250001 – 290001
- 3: 290002 – 320000
- 4: 320001 – 360000
- 5: 360001 – 410000
- 6: 410001 – 470001

You will find your setup code here
create table home_sales (
sale_date date,
price number(11, 2)
);
insert into home_sales (sale_date, price) values
(‘2013-08-01’::date, 290000.00),
(‘2014-02-01’::date, 320000.00),
(‘2015-04-01’::date, 399999.99),
(‘2016-04-01’::date, 400000.00),
(‘2017-04-01’::date, 470000.00),
(‘2018-04-01’::date, 510000.00);
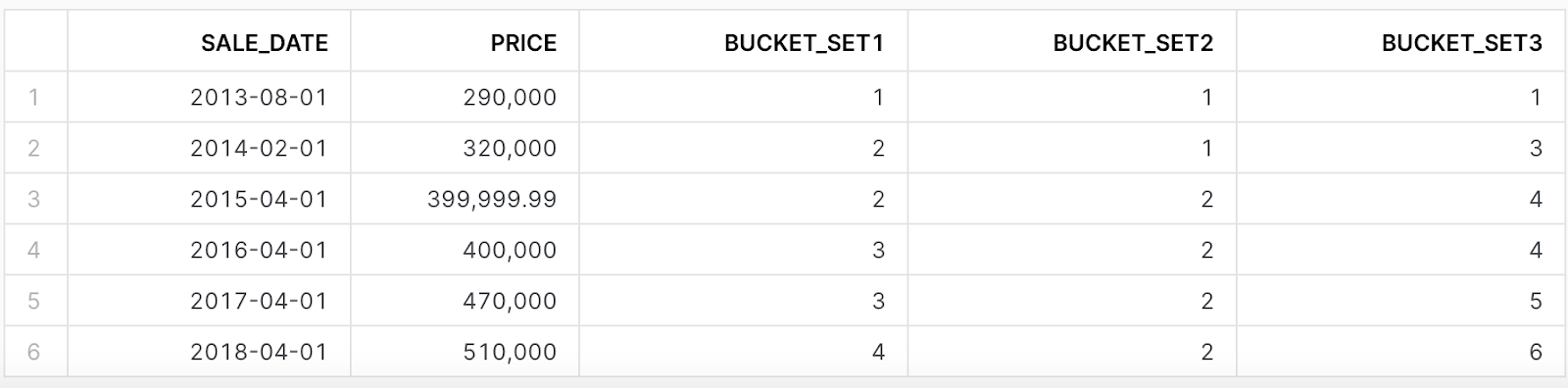
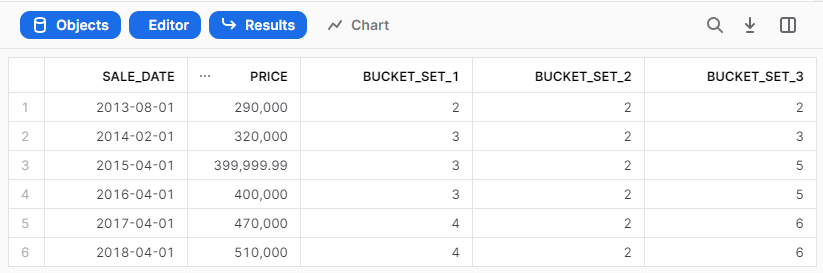
Given the buckets above, the following results should be generated:
Remember if you want to participate:
- Sign up as a member of Frosty Friday. You can do this by clicking on the sidebar, and then going to ‘REGISTER‘ (note joining our mailing list does not give you a Frosty Friday account)
- Post your code to GitHub and make it publicly available (Check out our guide if you don’t know how to here)
- Post the URL in the comments of the challenge.
You can also sign up to our mailing list below.
7 responses to “Week 15 – Intermediate”
-
Fun chance to demonstrate the advantages of Python-based UDFs
- Solution URL – https://github.com/ChrisHastieIW/Frosty-Friday
-
I used sql udf
- Solution URL – https://github.com/mateusz-kmon/frostyfridaychallenges/blob/main/w15.sql
-
My approach
– Create a base table to insert the values.
– Create a python udf (https://github.com/dsmdavid/frostyfridays-sf/blob/main/macros/ch_15_create_udf.sql) as a post_hook for the first table.
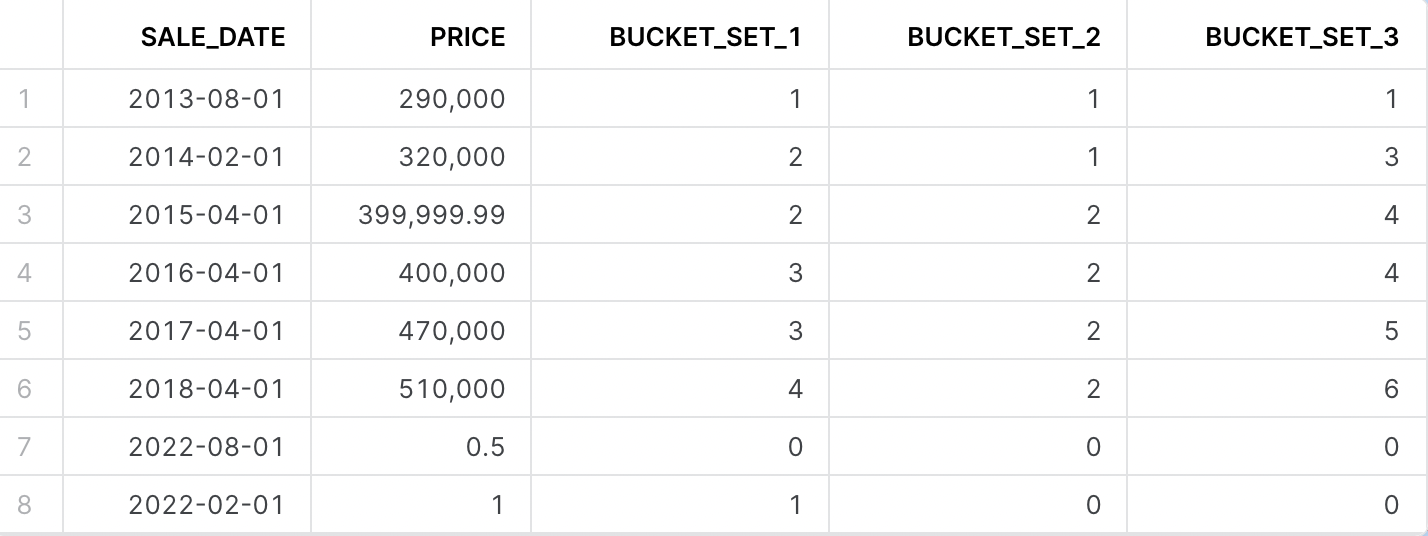
– Create a second view with buckets (https://github.com/dsmdavid/frostyfridays-sf/blob/main/models/challenge_15_02.sql)I also added some additional prices below the minimal threshold for edge cases (and assign a bin value of 0)
-
Another python solution!
- Solution URL – https://github.com/scallybrian/bs-frosty-sf/blob/main/frostyfridays/models/challenge_015/challenge_015
-
Here’s my sql-based udf.
- Solution URL – https://github.com/pekka-kanerva/frosty-friday/blob/main/week15/ff-week15-solution.sql
-
Also did mine in a python UDF. Although I set mine up to output null as the bucket if the price fell outside the range of all buckets.
- Solution URL – https://github.com/ChrisBo94/FrostyFriday/blob/main/Week_15.sql
-
🙂
- Solution URL – https://github.com/darylkit/Frosty_Friday/blob/main/Week%2015%20-%20UDFs/udf.sql

{kind=link}
Leave a Reply
You must be logged in to post a comment.