
Snowpark skills are going to be seen as more and more useful as time goes by, and for this reason, we’re posting another Snowpark challenge!
This week, we’re registering UDFs.
Your start-up code is below – it will create a table for you that has employees and their start dates.
Start-Up Code
create or replace file format frosty_csv
type = csv
skip_header = 1
field_optionally_enclosed_by = '"';
create stage w29_stage
url = 's3://frostyfridaychallenges/challenge_29/'
file_format = frosty_csv;
list @w29_stage;
create table week29 as
select t.$1::int as id,
t.$2::varchar(100) as first_name,
t.$3::varchar(100) as surname,
t.$4::varchar(250) as email,
t.$5::datetime as start_date
from @w29_stage (pattern=>'.*start_dates.*') t;You need to create a UDF that will produce a fiscal year for the start_date. The logic should be that if the month is from May onwards* then the fiscal year should be the current year + 1, otherwise, the current year.
For example:
2022-05-13 = FY23
2022-02-11=FY22
Once you’ve written your UDF, execute the following code:
data = session.table("week29").select(
col("id"),
col("first_name"),
col("surname"),
col("email"),
col("start_date"),
fiscal_year("start_date").alias("fiscal_year")
)
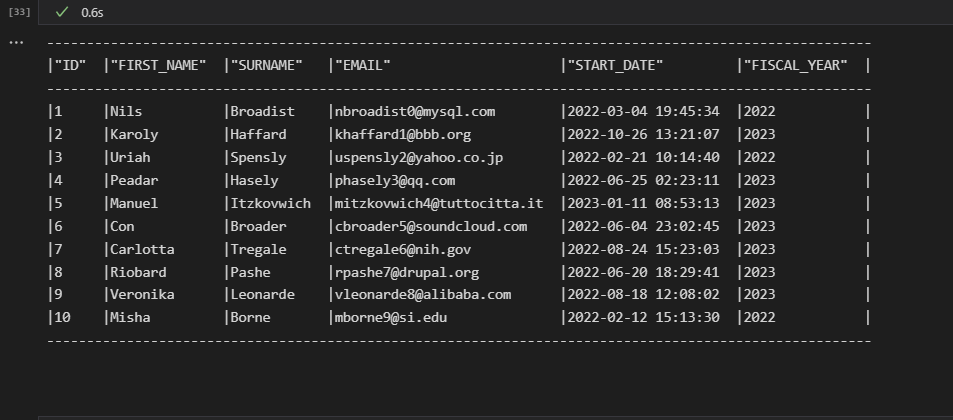
data.show()and
data.group_by("fiscal_year").agg(col("*"), "count").show()The result should look like, this:
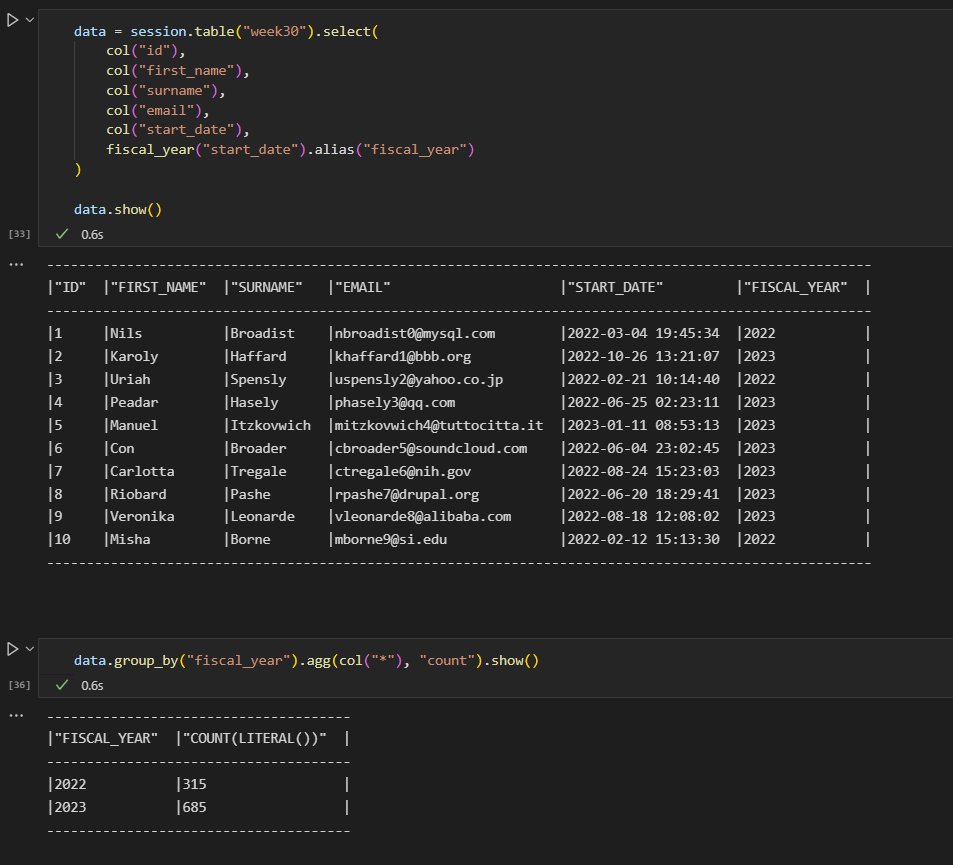
And there you have it!
*because we said so.
3 responses to “Week 29 – Intermediate”
-
An excellent challenge to come back to for the new year, happy 2023! I actually didn’t realise there was a challenge last week too, so I’ve got some catching up to do!
If anybody is looking for help on this challenge without seeing the solution itself, I would recommend my Definitive Guide to Creating Python UDFs in Snowflake using Snowpark, link below.
- Solution URL – https://github.com/ChrisHastieIW/Frosty-Friday
-
This is really interesting and not something I’m playing with enough, so thanks for the opportunity! (And also, a good reading from ChrisHastie 🙂
Bit of a convoluted approach here…
1) Create the base model to read the data (.sql, dbt)
2) Create and register the UDF (jupyter notebook, non-dbt) https://github.com/dsmdavid/frostyfridays-sf/blob/main/extra/ch29_udf_arbitrary_FY.ipynb
3) Create the final model that uses the UDF in a snowpark (.py, dbt)- Solution URL – https://github.com/apd-jlaird/frosty-friday/tree/main/week_29_02.py
-
Thanks for the challenge!
I modified the script for showing ‘data’ object with call_udf().- Solution URL – https://github.com/Atzmonky/snowflake/blob/main/ff29_udf.py

Leave a Reply
You must be logged in to post a comment.